Literate Programming Writ Large
People ask me if I’m still doing my literate devops. Yeah, after ten years, I still am. I find it helpful, and well, I like programming literate-ly.1
Over on Reddit, user idc7 posted a question on r/orgmode:
These [code blocks in org-mode] seems manageable when these blocks are simple, and just a couple of lines. But when they get bigger, and/or require other code from other blocks, it gets harder to maintain. … What am I missing? What do people do for this use case? Or is my use case wrong? Or even, isn’t emacs+orgmode the right tool?
In that Reddit post, Troll-Gpt observes:
You might find out for yourself why literate programming has not caught on as a software engineering paradigm, except some niche use-cases.
I don’t think anyone would tell you you’re doing something wrong; it’s just the approach is not scalable.
Interesting perspective, and troll-gpt is correct in stating that large projects increase in complexity. But, I’m wondering if large code bases could be more manageable with literate programming? At least, with literate programming as defined and implemented in Org.
This essay is about how I have made LP even better.
Advantages
What are the advantage of literate programming? I listed some in my essay and video about the literate devops idea, but perhaps a picture is worth more than prose:

While you can connect your code to your programming agenda, this screenshot shows the most compelling reason to use literate programming for managing large code bases:
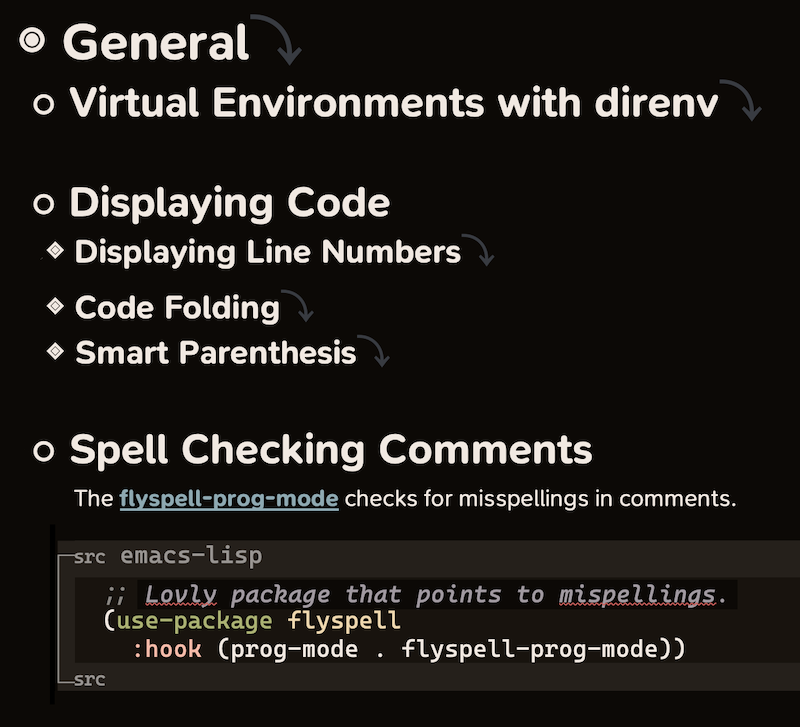
In this screenshot, you can see an example of a code base organized semantically and taking advantage of Org’s header collapse feature. Of course a well-written README can reference code concepts and organization, but what you are seeing in the screenshot above is the folded code.
Disadvantages
My largest literate-based coding project is over 8,000 lines of code. The surrounding prose adds 10,000 lines (where most of those lines are non-wrapped paragraphs). Is this large? Certainly not, not trivial. I literalized it precisely to deal with complexity.2
I’m not claiming that LP is any sort of panacea, but since I LP3 in Org-mode, which runs in Emacs, I can smooth some of the rough edges of my workflow by writing supporting functions.
The issues that I face most often include:
- Discrepancy between the literate file version and the resulting code file
- Evaluating code and maintaining code “state”
- Finding the code to edit
I was rather annoyed with this last issue, since I like to jump to a function’s definition using M-. How does one find a function’s definition if the function lives in a text file instead of a code file?
Addressing the Challenges
Let me talk about adjusting Emacs to fit my programming workflow, including syncing, evaluating and navigating my literate code.
You will find everything I describe here in my source code repository. Another advantage of having my Emacs init.el configuration code written in org files, is the ease of exporting to my website to share with others.
Syncing Code
After crafting an Org file with code blocks, we tangle the file to create a source code file. To make sure the code in your org file matches the source code file, place the following code at the bottom of your Org file. This automatically tangles when you save the file:
# Local Variables: # eval: (add-hook 'after-save-hook #'org-babel-tangle t t) # End:
We typically use this to set file-local variables when loading a file, but the eval sequence allows us to call Emacs functions. Note that when you first load a file like this, it will ask you if you want to run the code, and one of the options is to permanently allow that. I’m not encouraging such risky behavior, but …
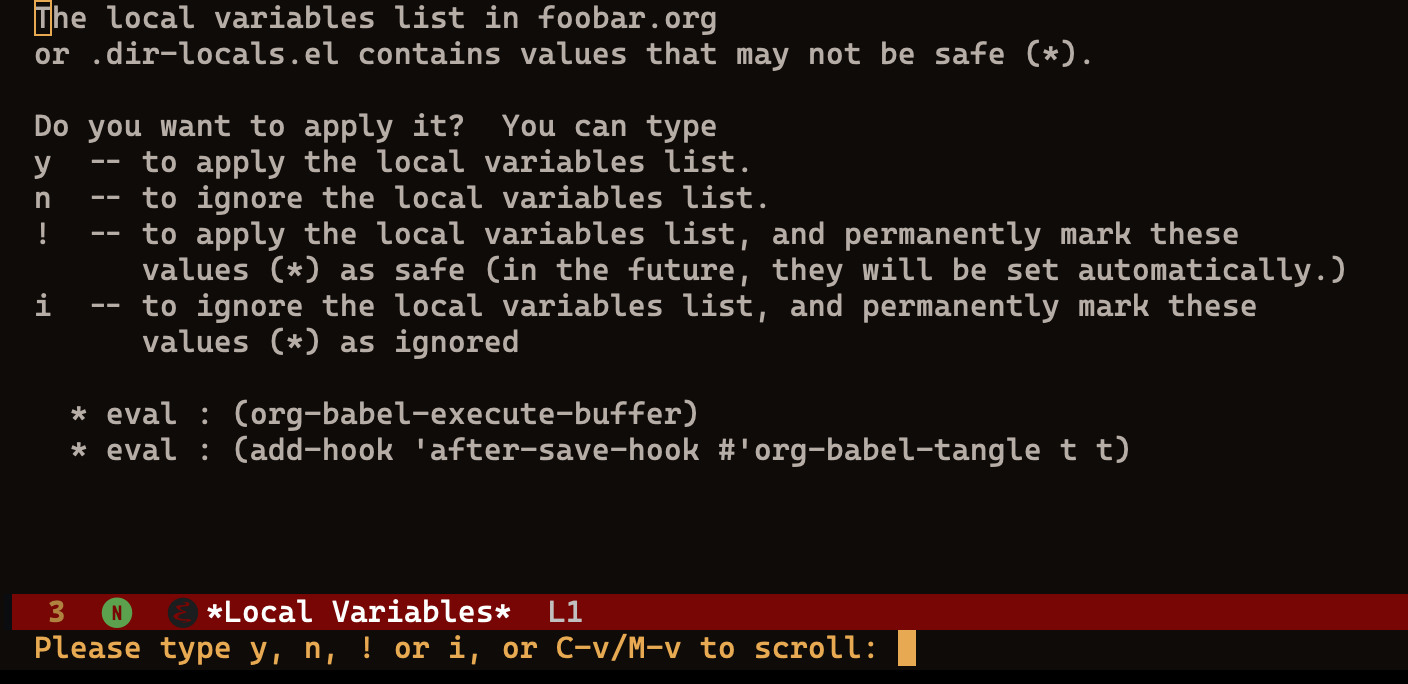
If you choose !, it adds the hook to the list of safe-local-variable-values by altering either your init.el, or your custom.el if you set the custom-file variable. I don’t want Emacs altering my init.el file like this, so I add this code in my early-init.el file:
(setq custom-file (expand-file-name "custom.el" user-emacs-directory)) (when (file-exists-p custom-file) (load custom-file))
When you are viewing the tangled file, call org-babel-tangle-jump-to-org to return to the original Org file.
A related idea…In the header-args property, set the comments header argument to link, to allow changes to your tangled code to update your original literate org file after calling M-x org-babel-detangle. For instance:
#+PROPERTY: header-args: :tangle yes :comments link
This tangle/detangle allows you to edit either representation of your code. See also the org-tanglesync project for putting a bit of controls around this feature. Personally, I haven’t used this feature, for as this essay shows, I’m happy editing solely in the Org file.
Evaluating Code
I assume you know you can evaluate code block’s in Org files in the language you tag by typing C-c C-c anywhere in the block. Here are some of my more advanced tips.
Sessions
Unless you are writing Emacs Lisp code4, I highly recommend setting a session. While you can do that in a property drawer per headline, you might as well set it in a property to have a session (per language)for the entire file:
#+PROPERTY: header-args:python :session foobar
This creates a buffer (in this case, *foobar*) and you can switch to that buffer and type in expressions, like a REPL for your language.
The following idea may be controversial, but you can call org-babel-execute-buffer when loading a file loaded to automatically evaluate all blocks when you load a file:
# Local Variables: # eval: (org-babel-execute-buffer) # End:
Personally, I find I would like to call this function manually instead of automatically. Perhaps give that function a keybinding. Using this feature means, when you load a file, you can directly start editing/evaluating code blocks and know that they are in sync with the other code blocks. YMMV
Evaluating Blocks
While you can move the cursor to a block and type C-c C-c to evaluate the block, we can use Avy to make this easier. The avy-jump function takes a regular expression, like (rx “#+begin_src”), and an :action (which could be a way to lightly jump to a block, and also call the function, org-babel-execute-src-block-at-point). Add this to your init.el.
(defun org-babel-execute-src-block-at-point (&optional point) "Call `org-babel-execute-src-block' at POINT." (save-excursion (goto-char point) (org-babel-execute-src-block))) (defun avy-org-babel-execute-src-block () "Call `org-babel-execute-src-block' on block given by Avy. Use Avy subsystem to select a visible Org source code block, e.g. `#+begin_src', and then executes the code without moving the point." (interactive) (avy-jump (rx "#+begin_src ") :action 'org-babel-execute-src-block-at-point))
Calling avy-org-babel-execute-src-block places a visual marker on every Org block.

Selecting a letter evaluates that code without moving your cursor.
Evaluating Sections
The function, org-babel-tangle, tangles the viewable text, and will tangle code the visible blocks after narrowing. Use the following function to evaluate all blocks under the current headline.
(defun org-babel-execute-subtree () "Execute all Org source blocks in current subtree." (interactive "P") (save-excursion (org-narrow-to-subtree) (org-babel-execute-buffer) (widen)))
This feature gives us finer grain control: between a single block (org-babel-execute-src-block) and an entire buffer (org-babel-execute-buffer).
Navigating by Section
In a large code base, we begin by organizing our code by library or module, and then each file contains a class composed of methods or functions and variables or fields. As I mentioned above, literate programming allows me to add a semantic organization layer where I can group related concepts under headlines (which can be nested).
With a few functions, I’ve created an user interface that allows me to search the header sections in my project and jump to that file.
In the screencast below, you notice that the file is the first part of the line, followed by the top-level header, then subheading under that.
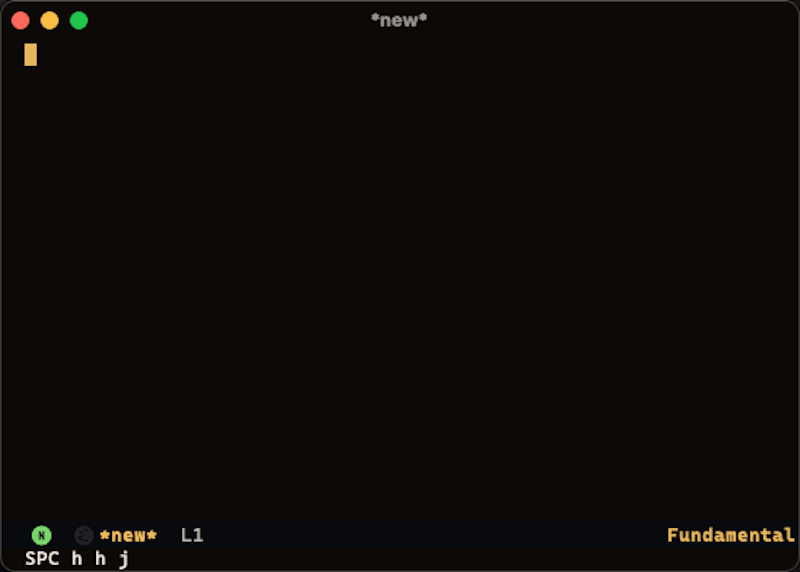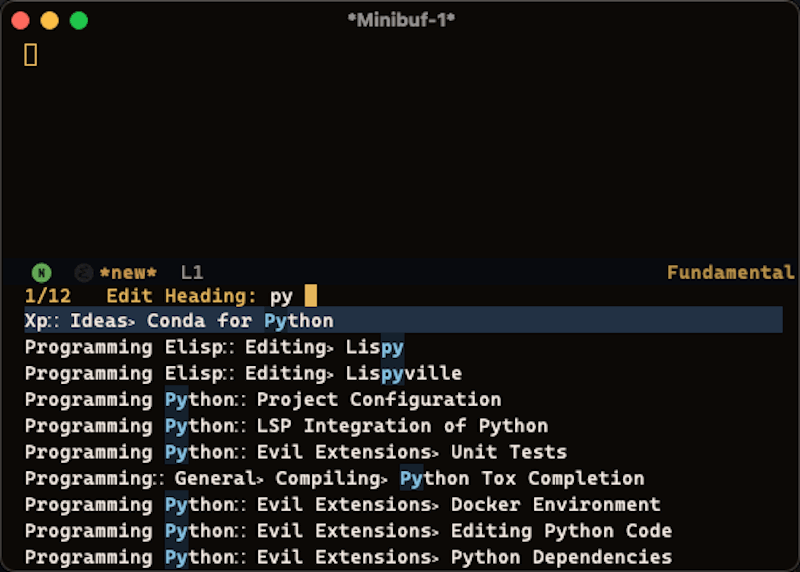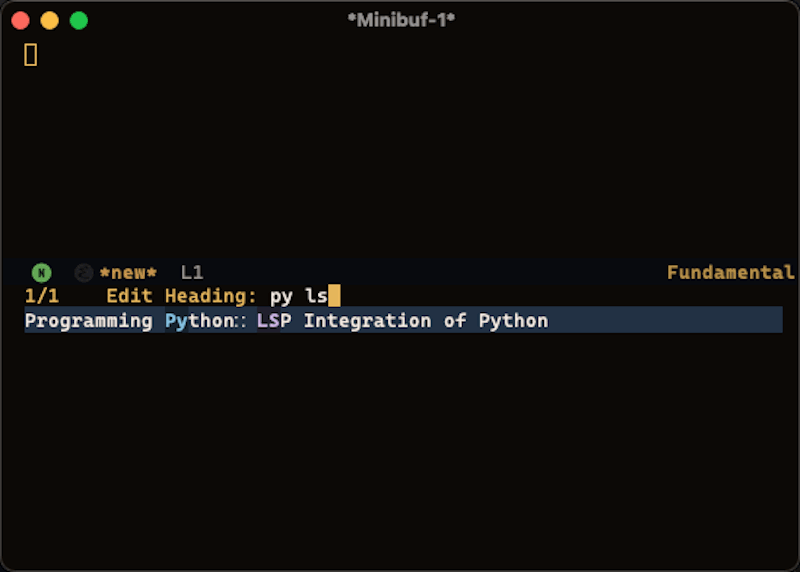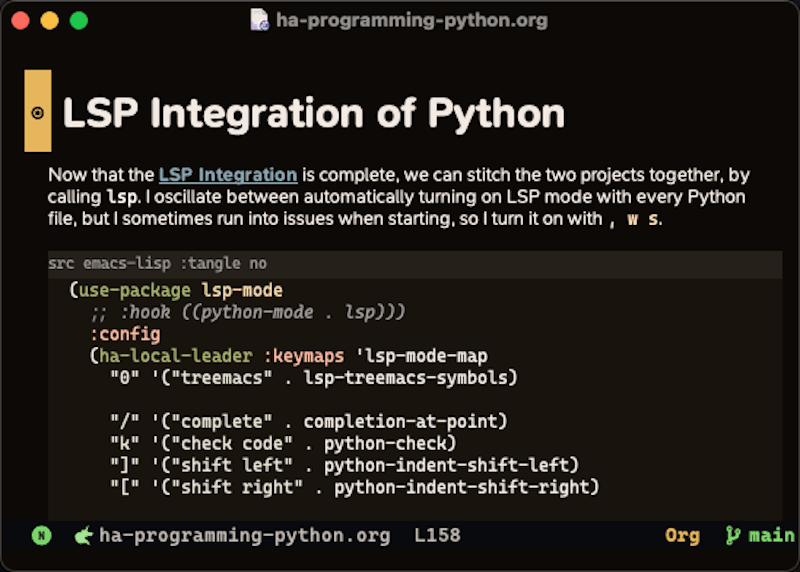
Using the fuzzy matching capabilities, I can type any combination of file/headline to narrow the scope to matching headers.
Feel free to steal the code for this here.
Navigating by Function Names
What about jumping directly to a function or class name? Often, we can see some code that calls a method on a class or a function, and we issue a call to xref-find-definitions (M-. … or if using Evli, evil-goto-definition). But these functions don’t understand that the source code can be located in Org files.
When jumping around in code we typically have three types of jumps:
- Definitions. This is often a quick jump to where you have defined a symbol (function, variable, class) that the cursor is on. Often you will have one result.
- References. Usually a list of function calls or variable usage is presented, allowing you to choose the one you want.
- All Usages (called apropos in Emacs parlance). A combination of both of the above, plus references in comments, etc. Again, often presented as a list to choose.
I want to jump around my code like this whether I was in an Org code block or in the surrounding prose. Inspired by the dumb-jump project that uses git-grep or ripgrep to quickly search a code base by symbol in real time, I wrote an extension to the xref API.
The first challenge was determining what a symbol could be. In most languages, that is straight-forward. In Python, only sequences of alpha-numeric and underscores, but in Lisp, one needs context, as almost any character sequence, starting and terminating with spaces or paren/braces defines a symbol. With literate programming, I want to be able to describe a function name in the prose so any of the following is possible:
The symbol, ~foobar~, defines what is. However, =foobar=, defines what isn't. As mentioned, the symbol (foobar) states much. But other functions, like foobar, are understated.
In the screencast below, you can see the point (cursor) on a symbol in the prose, and I can hit a sequence to jump to the definition in an org block:
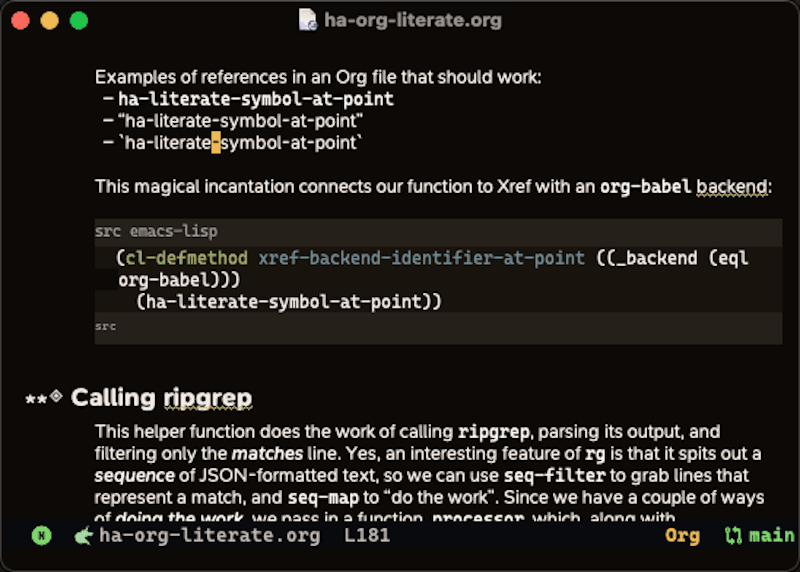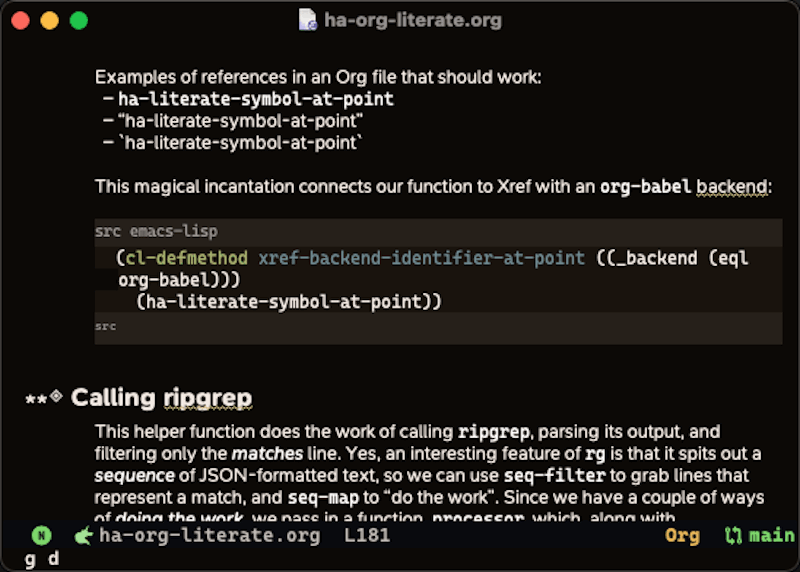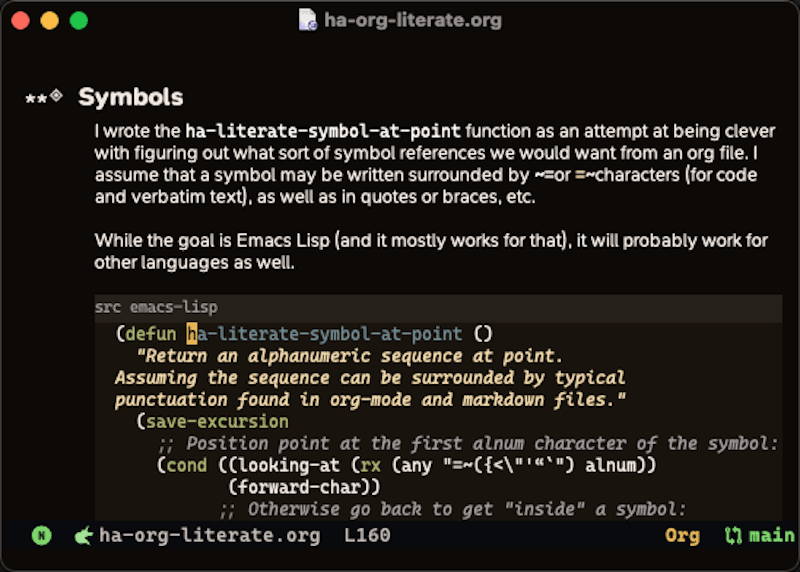
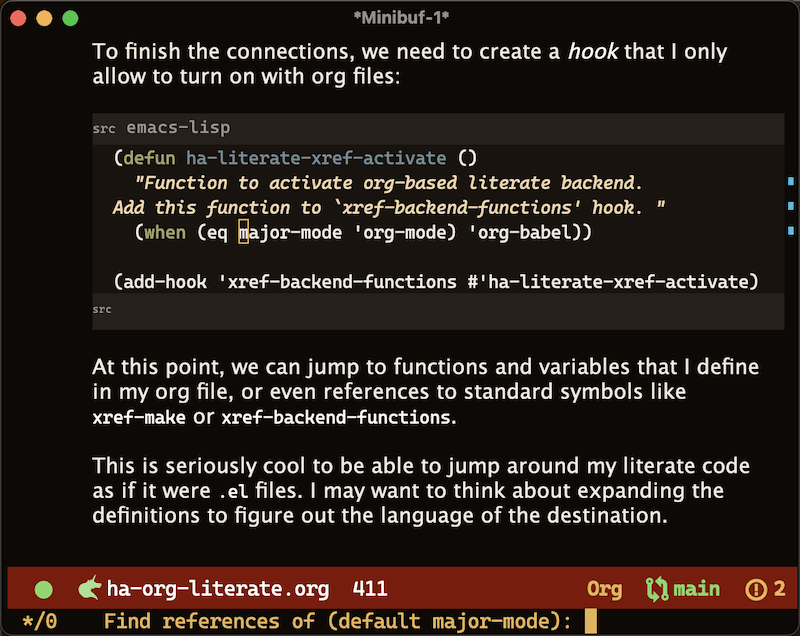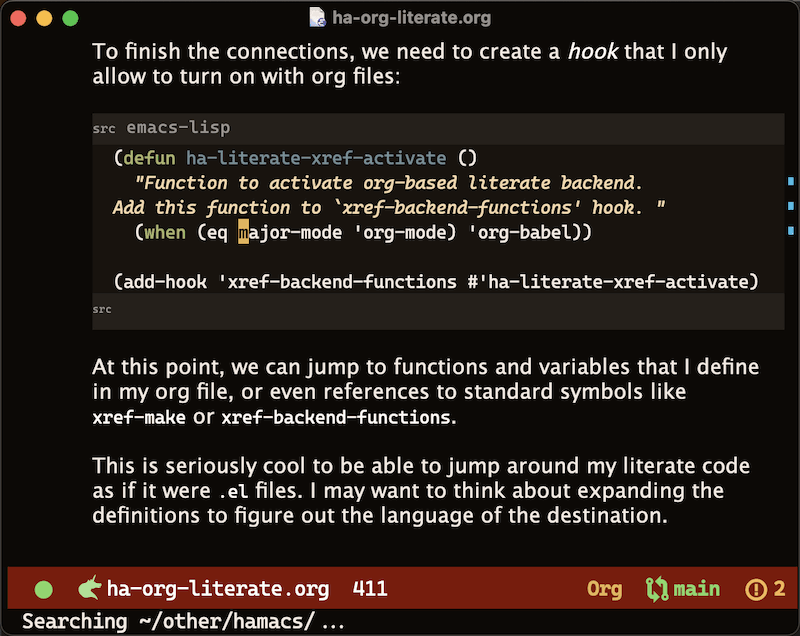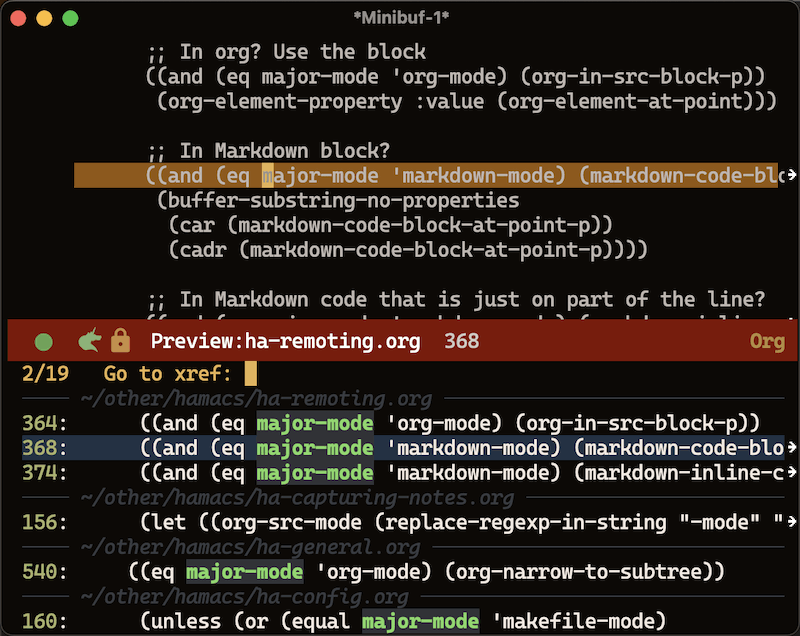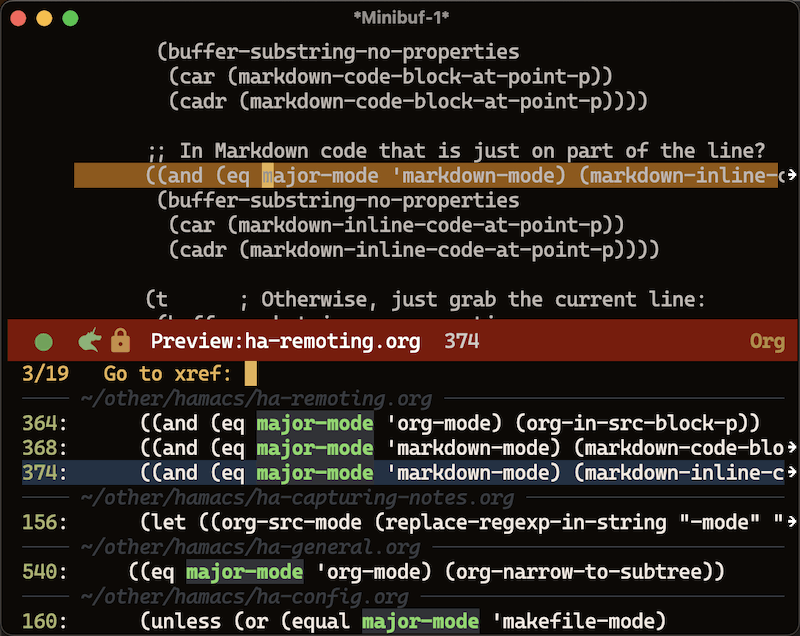
My next challenge was deciding how to take advantage of searching for references and apropos references. I decided that references would be limited to Org code blocks. The following is an example of selecting xref-find-references (M-?) on the symbol, major-mode:
I’m pleased with the results, but it isn’t perfect, so I’m leaving it in my personal Emacs configuration file, but hope to make a nice package on Melpa. Until then, feel free to steal this code too.
Summary
I work with a team of established engineers in a Fortune 500 company. Clearly, I don’t code literately in my day job … unless that code is for my own consumption, but I’ve noticed that for my own projects, I tend to begin with literate programming. Mostly because I know the least about a project when I start, and typing ideas before code crystallizes my thoughts.
As a project grows, I find the semantic structure of a hierarchical outline helpful when searching for code by concept, and find Emacs’ built-in code navigation useful when the code is in org files.
To make working with literate files, I have created the functions above, and call them using pretty-hydra with o s (for org source) which shows the following hints in the minibuffer:
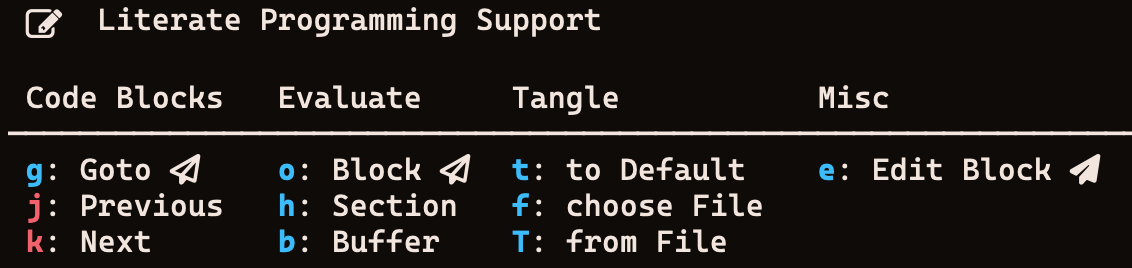
- The paper plane icons signify (to me) that these functions call Avy to either jump, evaluate, or edit a visible org code block.
I hope I have given you some encouragement to shave off any burrs on your workflow with literate programming, or at least, some food for thought for how best to manage complexity. Toot me to discuss your “pain points” and ideas for how I could make Xref work in a more general way.
Footnotes:
Can I turn literate programming into an adverb?
And now I get to use it as a verb!
That’s right, LP is now a verb too.
A side-effect of doing literate programming with Emacs Lisp, is it evaluates that code in your current Emacs. This could potentially render your Emacs session unresponsive. While possible, I don’t think I’ve ever caused this level of enjoyment before.






